
I’m a little salty that neither Anthropic nor Google reached out to me before they released their terminal-based AI coding agents.
You see until recently I was the CEO of Textualize, a startup promoting rich applications for the terminal. Textualize didn’t make it as a company, but I take heart that we built something amazing. There is now a thriving community of folk building TUIs that I am still a part of.
So you will understand why when I finally got round to checking out Claude code and Gemini CLI, I was more interested in the terminal interface than the AI magic it was performing. And I was not impressed. Both projects suffer from jank and other glitches inherent to terminals that Textualize solved years ago.
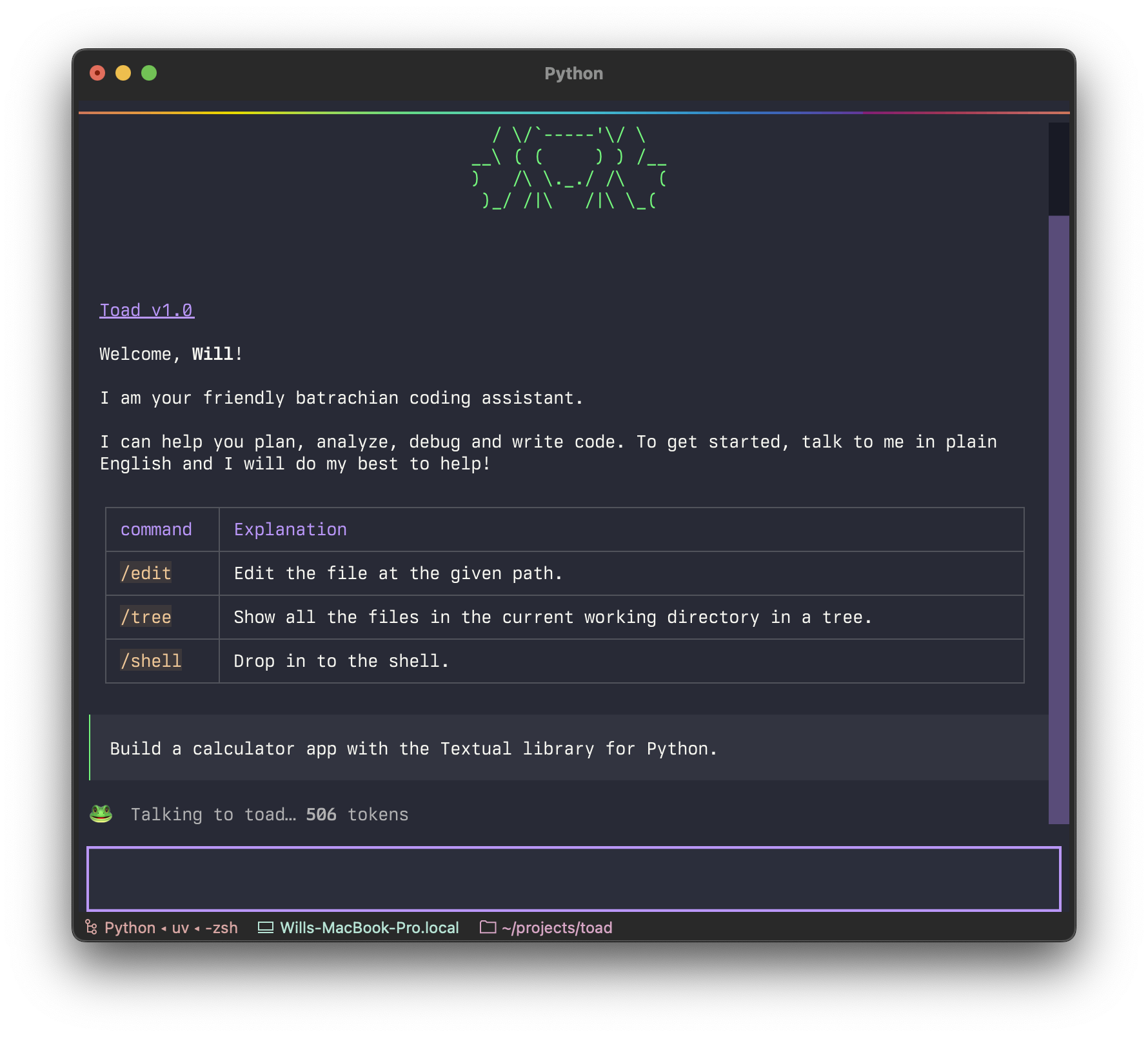
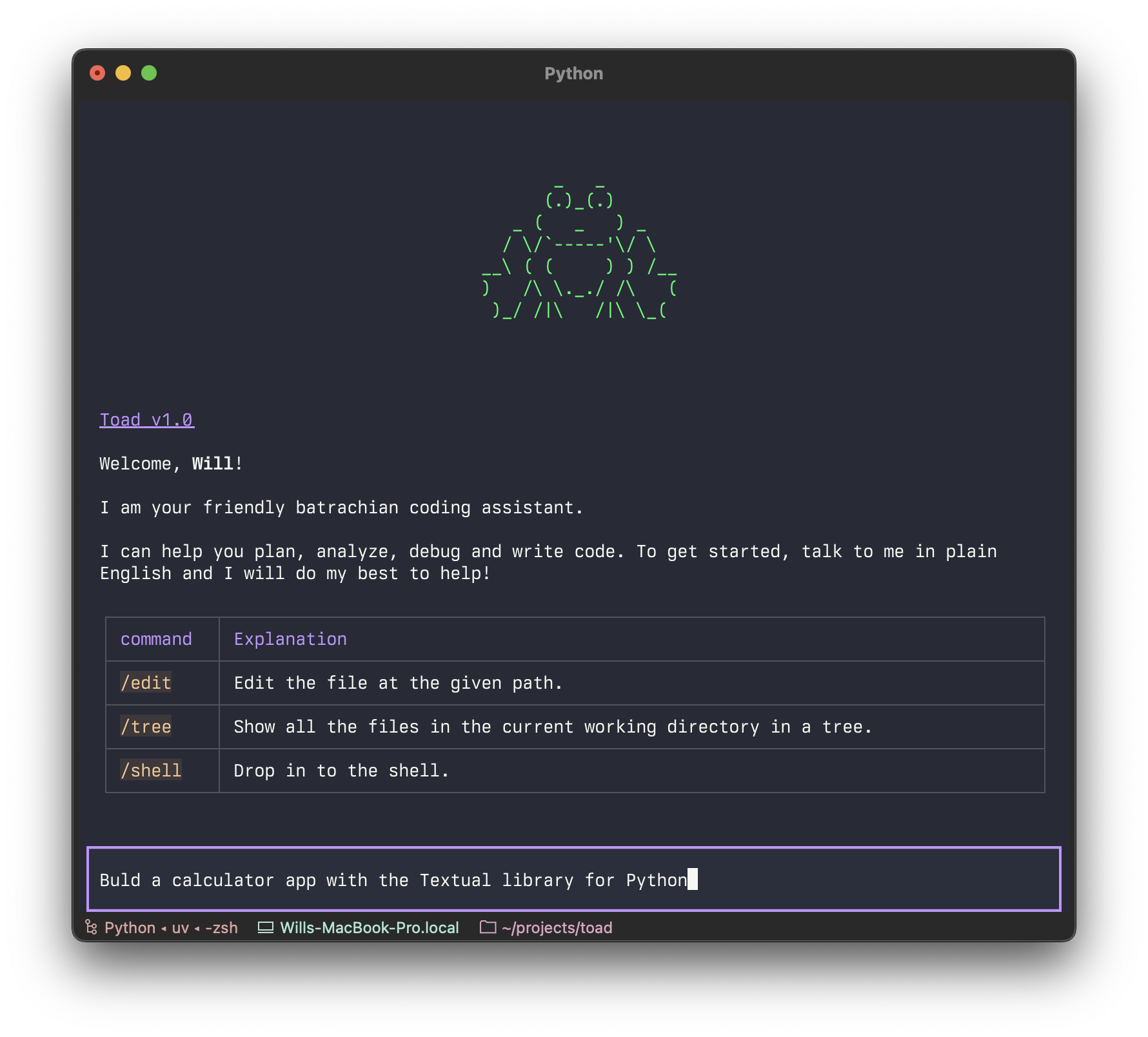
How did I react to this? I did what any well adjusted code-monkey would do in this situation. I built the following prototype across two afternoons in a nerdy caffeinated rage while listening to metal music.
 |
 |
 |
The rainbow throbber may be OTT. It might go.
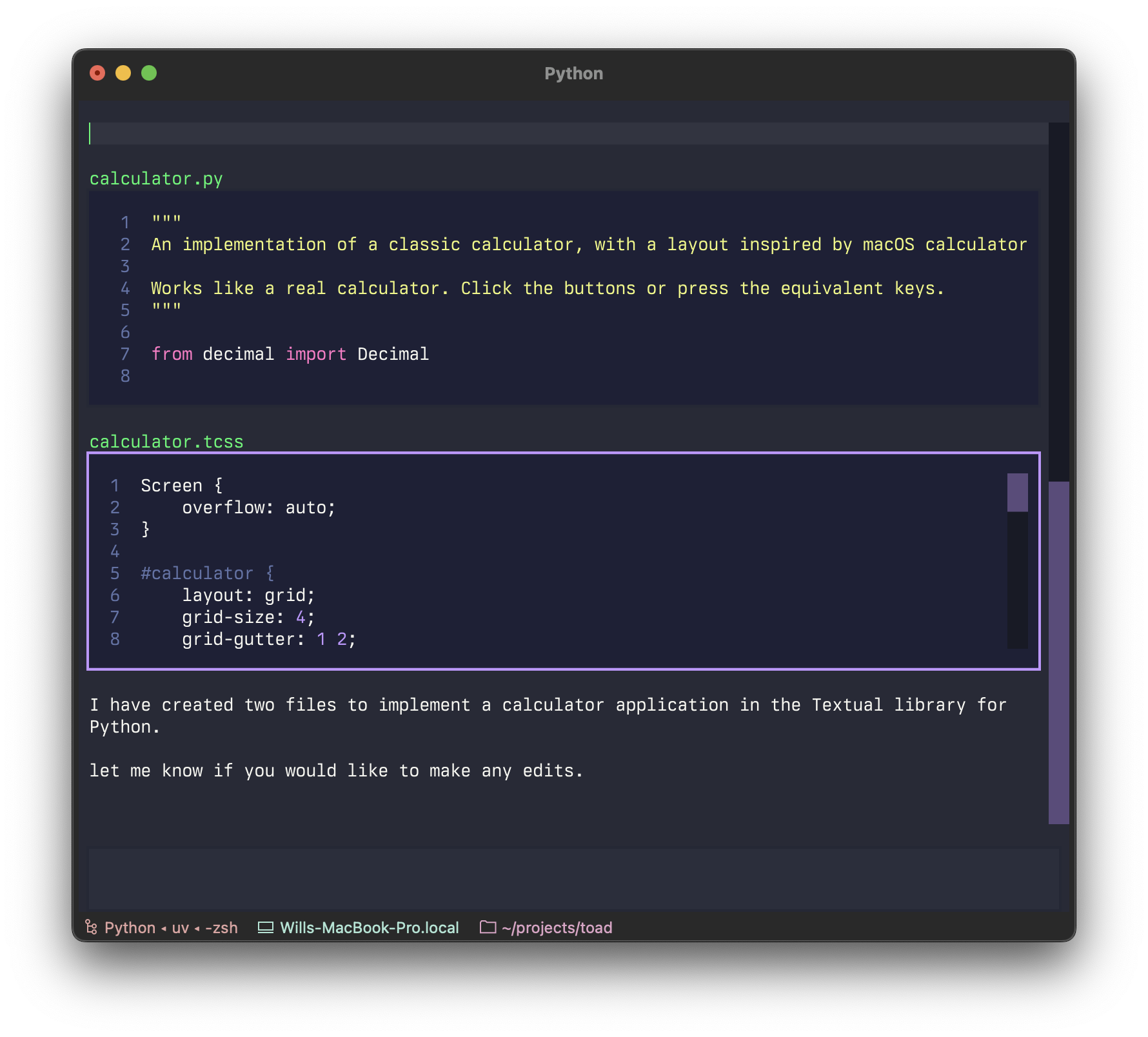
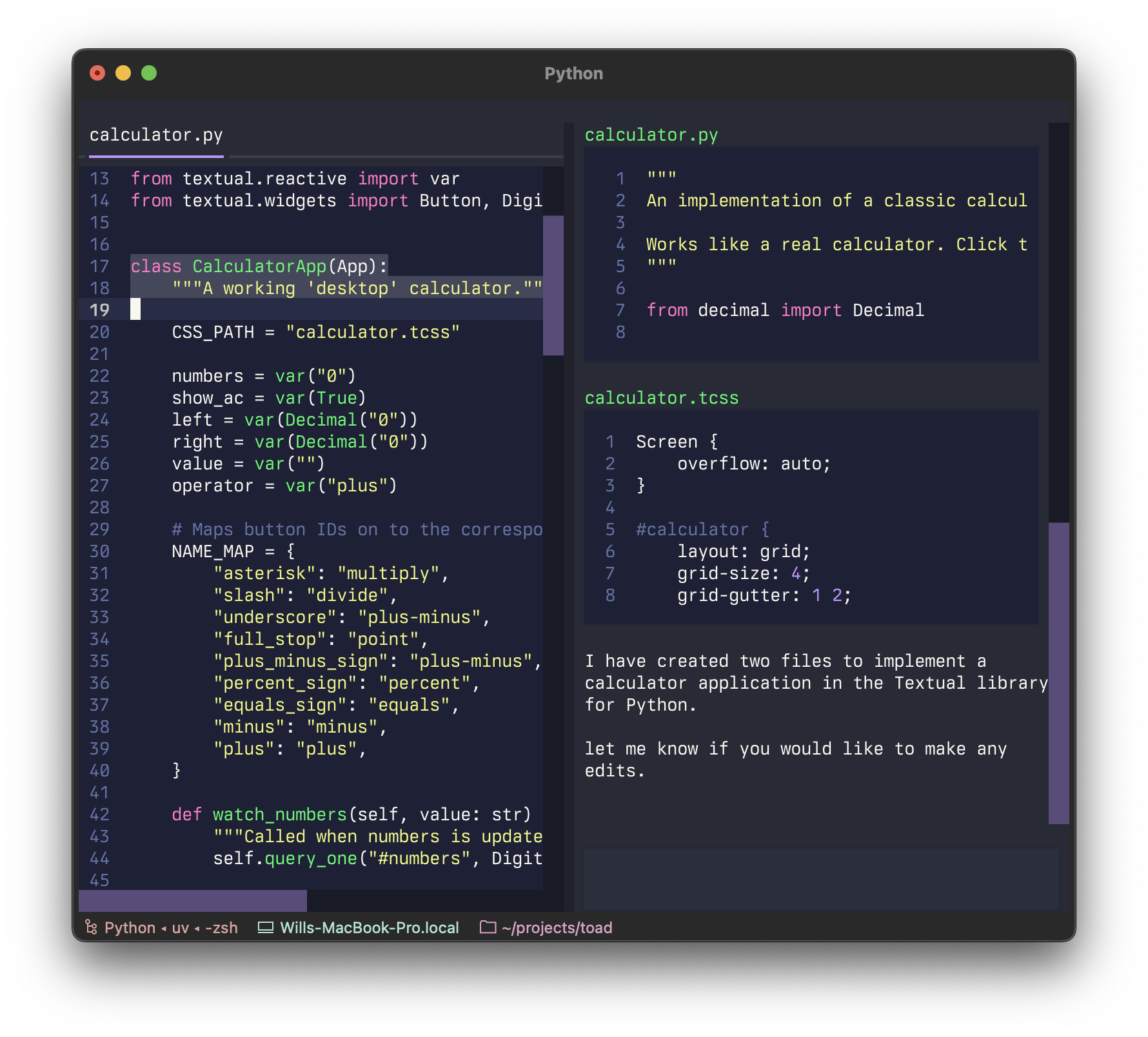
I called it Textual Code originally, which became “Toad” (the same way as Hodor got his name). Although purely a UI prototype with mocked up API interactions, it was enough for me to confidently say this is how you build a terminal based AI coding agent. We can have a jank free interface that remains light-weight and snappy without giving up the interactions we have all committed to muscle memory.
By “jank”, I mean anything happening in the UI which is unpleasant to the eye or detracts from the user experience rather than enhances it. Jank is typically a side-effect rather than an intentional design decision, since nobody would build in jank if they could avoid it. The prime example being flicker.
Both Anthropic and Google’s apps flicker due to the way they perform visual updates. These apps update the terminal by removing the previous lines and writing new output (even if only a single line needs to change). This is a surprisingly expensive operation in terminals, and has a high likelihood you will see a partial frame—which will be perceived as flicker. It also means that you can only update a maximum of a few pages before the flicker gets intolerable. After that, content is committed to the terminal’s scrollback buffer, and can’t be changed.
Not everyone is sensitive to the flicker, but there are other problems with this approach. If you resize the terminal, the output will be garbled if it doesn’t happen to be in the last portion the app is keeping up-to-date. And even if it isn’t garbled, you can’t select and copy more than a line of code without also copying line numbers, box drawing characters, and hard line breaks. In fact, you generally can’t interact with content in the scrollback buffer in any meaningful way.
Toad doesn’t suffer from these issues. There is no flicker, as it can update partial regions of the output as small as a single character. You can also scroll back up and interact with anything that was previously written, including copying un-garbled output — even if it is cropped. Here’s an example of text selection:
 This is in the terminal. Text selection and copying works even if the code is cropped.
This is in the terminal. Text selection and copying works even if the code is cropped.
This isn’t a feature of terminals per se. It is something the app has to manage itself. But the work has already been done in Textual.
So why didn’t big tech use Textual and Python to build their terminal agents? They would get text selection, smooth scrolling, flicker-free updates, app automation, snapshot testing, and a host of other features that would have meant they could ship a better product faster.
I suspect the main reason that the creators came from a pool of front-end developers, and they used the terminal libraries in that ecosystem. I am not unsympathetic to that. Generally speaking the best language is the language you are most familiar with. However now and again, the best language is the one with the best libraries. And when it comes to TUIs, Textual is so far ahead of anything in JS and other ecosystems.
Even if Python isn’t their thing, the architecture I have in mind would allow for the AI interactions to be in any language (more on that later).
I am clearly biased in this (massively so—I spent years working on Textual). But I maintain that if Anthropic and Google switched to Textual, they would overtake their current trajectory in a month or two.
Let me quickly debunk some arguments against using Python for these things, in bullet list form because you didn’t come here for tedious language wars…
- Python is slow. Python has gotten a lot faster over the years. And while it doesn’t have the performance of some other languages, it is more than fast enough for a TUI. Textual runs just fine on a Raspberry Pi.
- Python apps are hard to share. This used to be true. But now we have UV which can install cross-platform Python apps is easy as
npx. - Python startup time is slow. There is some truth in this, although we are only talking 100ms or so. I don’t see any practical difference between Python and JS apps on the terminal.
Licking the Toad
I’m currently taking a year’s sabbatical. When Textualize wrapped up I genuinely thought I was sick of coding, and I would never gain be able to find joy in building things. I’m happy to be wrong about that. I still enjoy coding, and Toad feels like the perfect hobby project for my very particular set of skills. Something I can build while continuing to focus on my physical and mental health (running a startup is taxing).
So I am going to build it.
I am building it.
Here’s a quick video of Toad in its current state:
What I have in mind is a universal front-end for AI in the terminal. This includes both AI chat-bots and agentic coding. The architecture I alluded to earlier is that the front-end built with Python and Textual connects to a back-end subprocess. The back-end handles the interactions with the LLM and performs any agentic coding, while the front-end provides the user interface. The two sides communicate with each other by sending and receiving JSON over stdout and stdin.
There are a number of distinct advantages in this approach. The back-end can be in any language you wish. And as separate processes, both sides have exclusive access to a cpu core (no more waiting for the app to finish doing its thing before you can interact with it).
This separation also allows for the front-end to be swapped out. In the future there may be a Toad desktop app, a mobile app, or a web app.
But perhaps even more exciting is that once the protocol has been defined, the transport could be swapped out. The front-end can be on your local machine, talking to a back-end on another box over encrypted transport. This may sound like SSH, but doesn’t suffer from any latency, as your UI is still running locally.
Since the back-ends don’t have to concern themselves with the UI, they can be implemented in a procedural style, making them easy to develop and test. And as accessible to solo developers (my people) as they are to big tech.
I would expect there to be a library available for each language that provides some syntactical sugar over the JSON protocol. Here’s some possible examples of such a library (in Python, but it could just as easily be JS or Rust):
Streaming Markdown
This would stream the markdown in realtime.
for chunk in response:
toad.append_markdown(chunk)
Asking questions
This would replace the text prompt with a simple menu, and return the result.
options = [
"Commit this code.",
"Revert the changes.",
"Exit and tell the agent what to do"
]
response = toad.ask(
f"I have generated {filename} for you. What do you want to do?",
options
)
Launching an editor
This would launch an editor, either inline in the Toad UI or an external editor depending on configuration. The user could then edit the code and return the update when saved.
if toad.ask(
f"Edit {filename} before committing?"
):
code = toad.edit(code)
Want to try Toad?
Toad isn’t quite ready for a public release. It remains a tadpole for now, incubating in a private repository. But you know I’m all about FOSS, and when its ready for a public beta I will release Toad under an Open Source license.
Until that time, you can gain access to Toad by sponsoring me on GitHub sponsors. I anticipate Toad being used by various commercial organizations where $5K a month wouldn’t be a big ask. So consider this a buy-in to influence the project for communal benefit at this early stage.
With a bit of luck, this sabbatical needn’t eat in to my retirement fund too much. If it goes well, it may even become my full-time gig.
I will shortly invite a few tech friends and collaborators to the project. These things can’t be the work of a single individual and I am going to need feedback as I work. If you would like to be a part of that, then feel free to reach out. But please note, I would like to prioritize folk in the Open Source community who have potentially related projects.
For everyone else, I will be posting updates regularly here and on my socials (link at the bottom of the page). Expect screenshots, videos, and long form articles. Please be patient—you will be agentic toading before too long.
Looking for markdown streaming?